Preemptive Solving of Future Problems: Multitask Preplay in Humans and Machines
During offline replay, humans and AI agents simulate pursuit of goals they did not pursue — caching solutions into a shared predictive representation that explains a counterintuitive human bias and improves RL generalization to 10,000 unseen worlds.
 1Kempner Institute · Harvard
1Kempner Institute · Harvard
 2Psychology & CBS · Harvard
2Psychology & CBS · Harvard
 3CSE · Michigan
3CSE · Michigan
 4LG AI Research
4LG AI Research
People are faster at new tasks when they reuse an old path — even when the reused path is longer than the optimal shortcut. We argue this happens because, during offline replay, humans and AI agents simulate goals they didn't pursue — caching solutions into a shared predictive representation. The same algorithm explains a behavioral bias in people and scales an RL agent to 10,000 unseen Craftax worlds.
- Algorithm. Multitask Preplay: replay one task; preplay the goals you observed but didn't pursue; cache the resulting solutions into a shared predictive representation.
- Behavioral evidence. Across five behavioral experiments in grid-worlds and 2D Minecraft (Craftax) — n=100 each, with preregistered predictions — people behave as if they have preemptively rehearsed goals before they encounter them: lower response times at familiar junctures pointing toward an unannounced goal, and partial reuse of old paths even when a shorter route is available.
- AI scaling. Beats Dyna, Universal Value Function Approximators (UVFA), Universal Successor Feature Approximators (USFA), and Hindsight Experience Replay (HER) on transfer to 10,000 held-out Craftax environments.
- Bridging. One computational idea — offline counterfactual simulation — connects a human behavioral bias to RL generalization, a template for AI and cognitive science to keep informing each other.
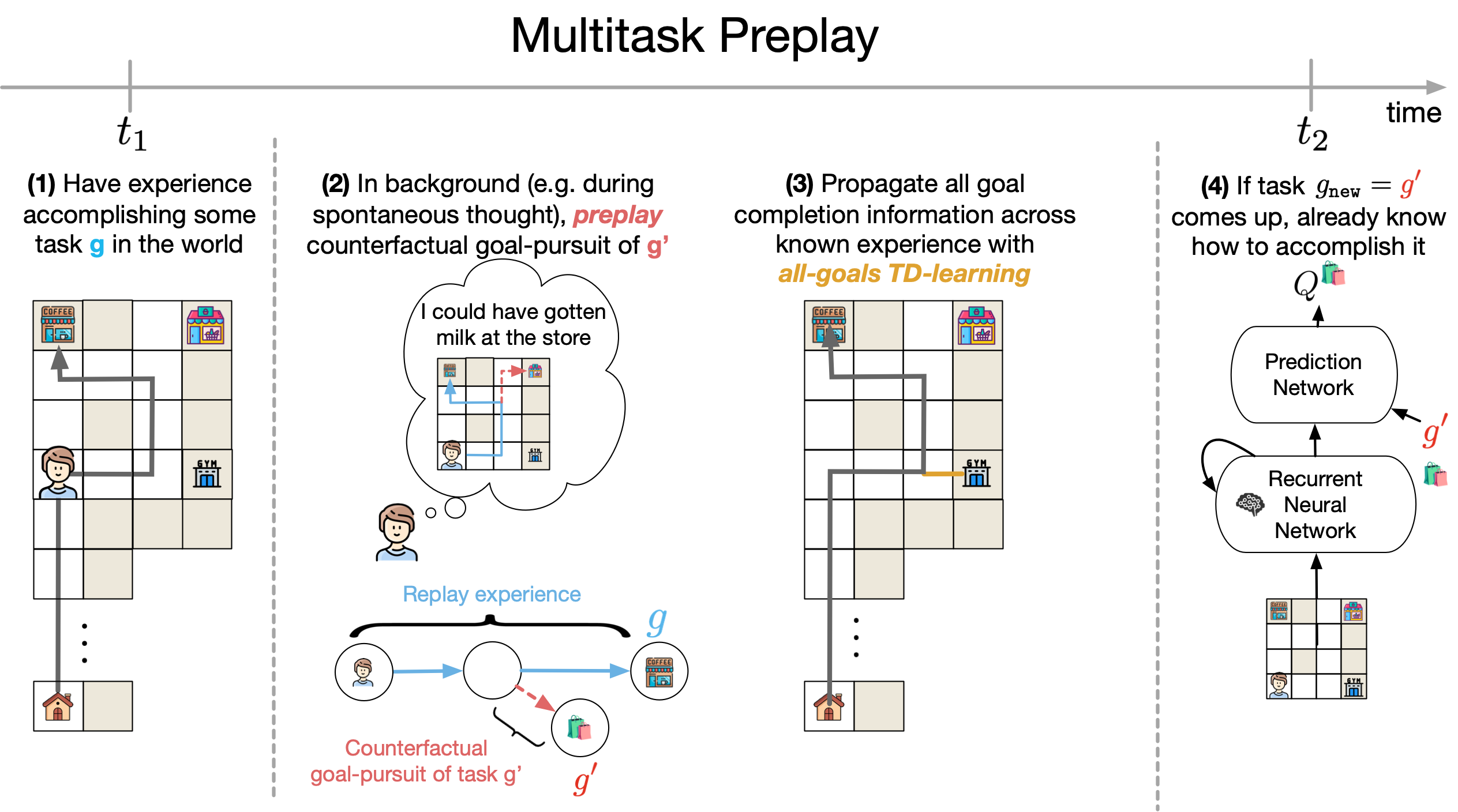
Preplay the goals you didn't pursue.
Do RL agents really need to replan from scratch for every new goal? Why do rodents "preplay" goals they haven't pursued?
While searching for coffee in a new neighborhood, you may come across gyms, grocery stores, and parks — enabling you to quickly find these locations later when you need them. You weren't told to look for the grocery store. But when the goal becomes "go to the grocery store," your behavior is fast and reactive, as if you'd planned the route already.
We hypothesize this happens because, during offline replay, you imagine pursuing goals you encountered along the way but didn't actually pursue. Those counterfactual trajectories cache solutions into a single value function that covers many goals. We call it Multitask Preplay — a nod to hippocampal preplay, where place cells fire for places the animal hasn't been yet (Dragoi & Tonegawa, 2011). The underlying RL idea goes back to Kaelbling (1993): use one experience to learn about many goals. We wanted to see what it looks like at scale.
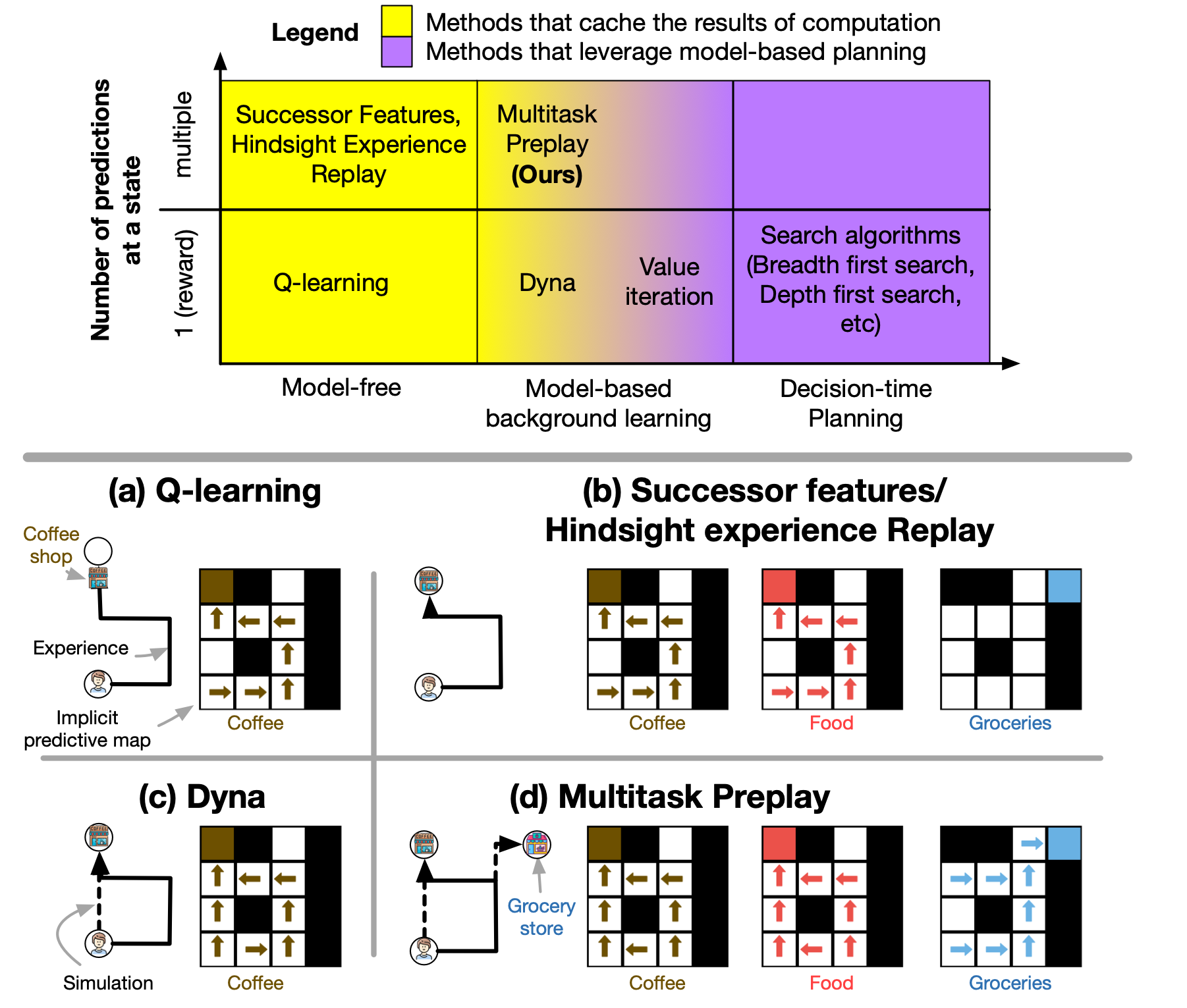
Multitask Preplay generalizes Dyna (Sutton, 1990), which only caches a value for the goal you pursued. It keeps Dyna's model-based simulation and adds what successor features (Barreto et al., 2017) do well — predictive representations that span goals.
People behave as if they've rehearsed goals before they encounter them.
We trained people on one set of tasks, then tested them on different ones. In principle, you'd rehearse tasks you expect to face. In practice — across five behavioral experiments in grid-worlds (JaxMaze) and 2D Minecraft (Craftax), n=100 each, with preregistered predictions — people behave as if they've rehearsed goals they were never told about.
The headline finding: the same person is faster at the same novel task when starting from a familiar location than from an unfamiliar one — even when both starts are equally far from the goal. Under Multitask Preplay this is expected: someone who passed that juncture during training would have preplayed routes from it to nearby goals, so the route is already cached when the test arrives. The alternatives predict no such advantage — under decision-time planning, for example, response times should be approximately equal from either start. Only Multitask Preplay predicts the familiar-juncture speedup.

The juncture-spawn advantage is one signature; partial path reuse is another. Give a person a new goal near an old route, and they don't take the optimal shortcut — they partially reuse the trained path. We observe this even when the reused path is longer than the available shortcut: in our path-reuse experiment, the reused path runs 61 steps against a 55-step shortcut, and subjects still partially reuse the trained path 62.8% of the time, with lower step-by-step response times on the reused segment.
To test whether this is generic habit or something specific to multi-goal preplay, we benchmarked humans against a panel of RL methods in Craftax. Humans and Multitask Preplay cluster at high success and high path reuse; Dyna, UVFA, USFA, and HER generalize but don't reuse paths the way humans do.
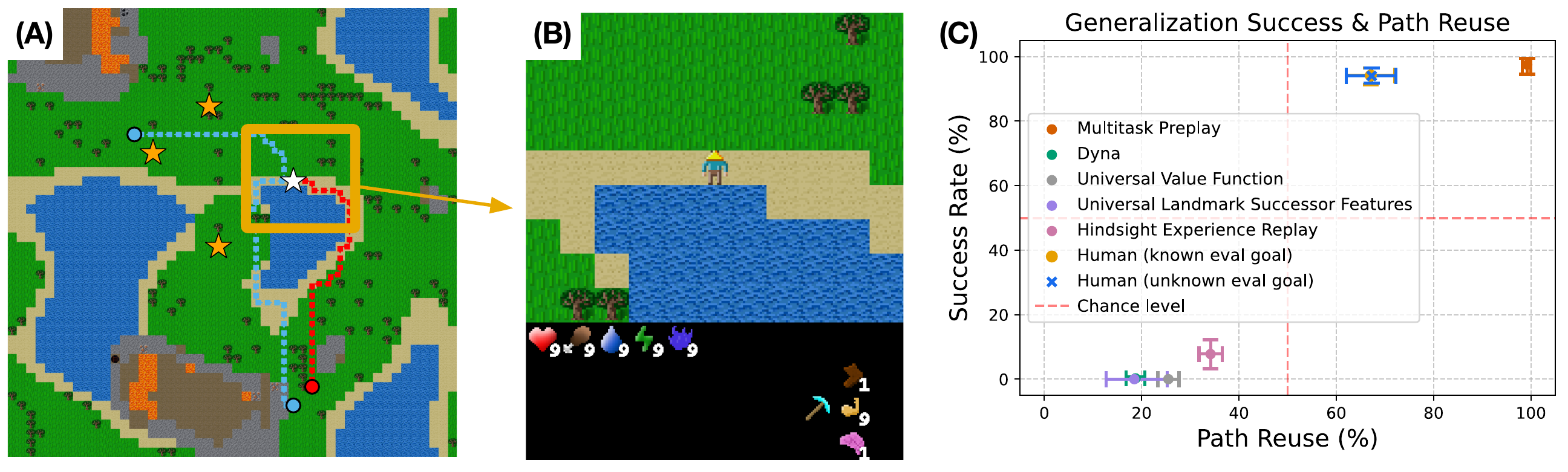
Only humans and Multitask Preplay survive the train-to-test cliff.
The result we found most telling: in Craftax, every baseline — Dyna, UVFA, USFA, HER — reaches near-perfect success during training. At test, only humans and Multitask Preplay transfer. Every other method collapses.
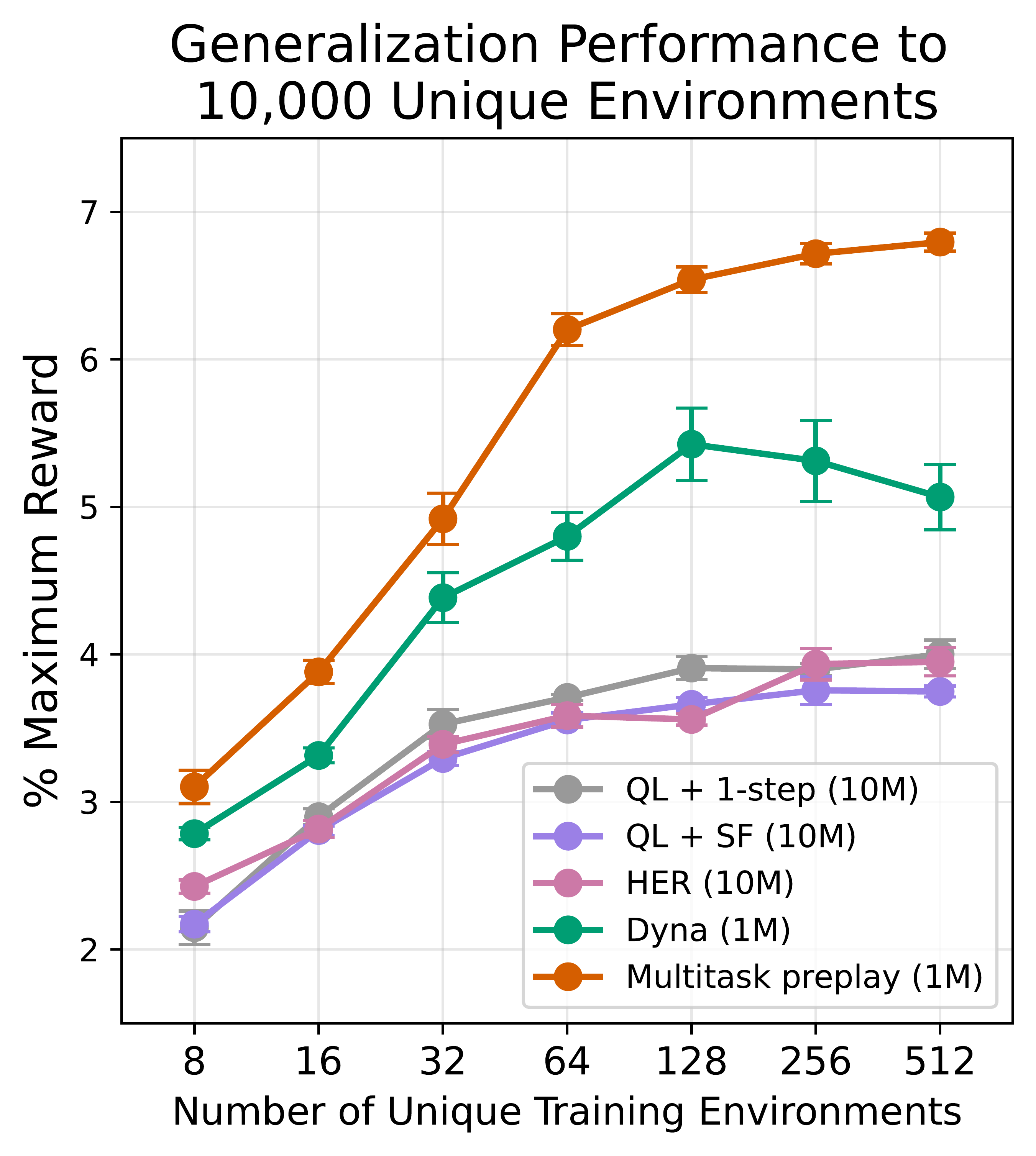
One agent, 10,000 unseen worlds.
This same algorithm scales further. Trained on a fixed set of environments, Multitask Preplay generalizes to 10,000 unseen Craftax worlds — and its test performance keeps climbing as training environments are added, while Dyna and model-free methods plateau at lower performance.
Two signatures in different systems, one computational idea underneath.
The same trick that explains a behavioral bias in people also scales an RL agent to unseen worlds. We're hopeful this is a template for how AI and cognitive science can keep informing each other: a computational-level claim that constrains both the algorithm space (in RL) and the hypothesis space (in cognitive science).
What this work doesn't do.
You need a reasonably accurate world model to preplay with. Multitask Preplay assumes access to a model that can roll out trajectories toward counterfactual goals during offline replay. We use ground-truth simulators in this paper. Whether the result holds when the world model itself is learned online — and how preplay interacts with a noisy or biased model — is not established here.
Tested on 2D environments with discrete tasks. Our results span gridworlds and 2D Minecraft. Whether the same algorithm scales to high-dimensional continuous control or to compositionally complex task structures — say, many interrelated tasks in unseen 3D homes — is the natural next step, but it's not what we showed.
Behavioral evidence is consistent with preplay, not unique to it. Our behavioral predictions are derived from Multitask Preplay, and the data are consistent with those predictions. Other algorithms that share its core ingredient — off-policy multi-goal value caching with TD learning — may make similar predictions. What we can say: among the baselines we compared, Multitask Preplay alone matches both human path-reuse rates and the train/test cliff.
Learned world models, then unseen homes.
Next we want to see what happens when the world model is learned online — for example, with MuZero — and to scale to domains like Habitat, where agents need to perform interrelated tasks in unseen homes.
Scaling to Habitat will lean on two corrections we developed along the way: off-task Q(λ) and conservative all-goals learning. They're what let us match the human data — and what we think will unlock Habitat-class transfer.
Methods (for the technically curious)
Off-task Q(λ). Propagates multi-step returns across goals the agent didn't pursue — a correction on Peng's Q(λ), applied on the goal axis instead of the policy axis. The trace is cut when the greedy actions for the off-task goal diverge from the actions actually taken, preventing erroneous backup of value from on-task rewards that don't apply to the off-task goal.
Conservative all-goals learning. Keeps value estimates from drifting when extrapolating to unseen goals. Penalizes Q-values for actions absent from the data, suppressing inflated estimates while still propagating value from the true off-task reward.
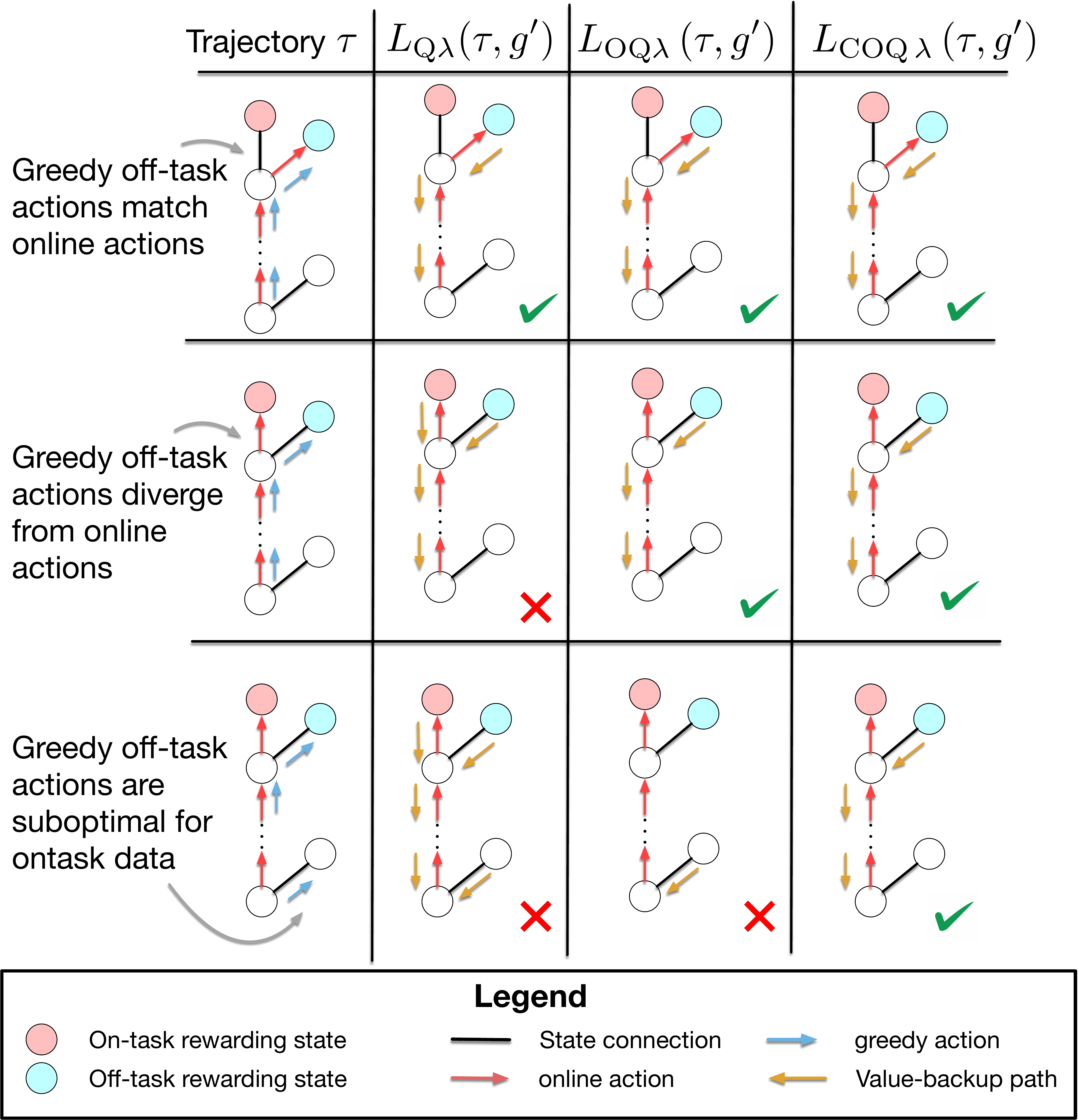
Both corrections are drop-in on a Dyna backbone. Full derivations + ablations in §Methods of the paper. Reference implementation in github.com/wcarvalho/multitask_preplay.
BibTeX
@article{carvalho2025preemptive,
author = {Carvalho, Wilka and Hall-McMaster, Sam and Lee, Honglak and Gershman, Samuel J.},
title = {Preemptive Solving of Future Problems: Multitask Preplay in Humans and Machines},
journal = {arXiv preprint arXiv:2507.05561},
year = {2025},
}