Task diversity produces systematic transfer
but inhibits continual reinforcement learning
Task variety is supposed to make reinforcement learning agents generalize. Across a changing sequence of tasks, we find the reverse: past a point, more variety makes an agent plateau at a lower level. It keeps learning each new set of tasks, but stops gaining from one set to the next.
 1Kempner Institute · Harvard
1Kempner Institute · Harvard
 2Harvard College
2Harvard College
 3University of Washington
4Psychology & CBS · Harvard
3University of Washington
4Psychology & CBS · Harvard
Each Banyan world is a map the agent moves through, paired with a goal that splits into sub-goals arranged as a tree. The agent sees only the top goal, never the tree, and has to discover the order things must be done.
Variety is the standard route to generalization
In machine learning, a striking pattern has emerged across settings: training on diverse task distributions consistently enables generalization to new ones, without additional training. Tobin et al. (2017) demonstrated this first in robotics, showing that varying an environment's visual and physical properties during simulation training was sufficient for policies to transfer to real robots. At larger scale, the Open Ended Learning Team (2021) trained agents across a vast space of games and found they solved millions of unseen games with no extra training. Jha et al. (2025) extended this logic to multi-agent coordination, showing that diverse task sets during training enabled zero-shot coordination with entirely new partners. Each result points the same direction: the breadth of training experience, not its depth on any single task, is what drives generalization.
In cognitive science, Fodor and Pylyshyn (1988) identified systematicity as a core property of cognition that connectionist models were thought to lack. Hill et al. (2019) provided early evidence that diversity in the training environment, not architecture, drives systematicity in situated agents. Lake and Baroni (2023) then answered the challenge definitively, showing that the right training task distribution induces human-like systematic generalization in neural networks, with direct comparisons to human behavior. This body of evidence converges on a clear principle: task diversity is the lever. What it leaves open is whether that lever works only at training time.
However, almost all of this evidence tests an agent after training has stopped, with its weights frozen. Far less is known about what task variety does while the agent is still learning, as it moves through one new environment after another. Banyan is built to study exactly that.
Banyan: turn the ingredients of a task into dials
A Banyan task is a small world the agent moves through, plus a goal. The goal splits into sub-goals arranged as a tree. We control three ingredients independently: the map layouts (𝕃) the agent navigates and the task-tree topologies (𝕋) that set how sub-goals depend on one another. A third axis, task-tree object assignments (𝕆), decides which concrete objects fill each sub-goal. This design lets us pin an effect on a specific kind of variety rather than on variety in general.
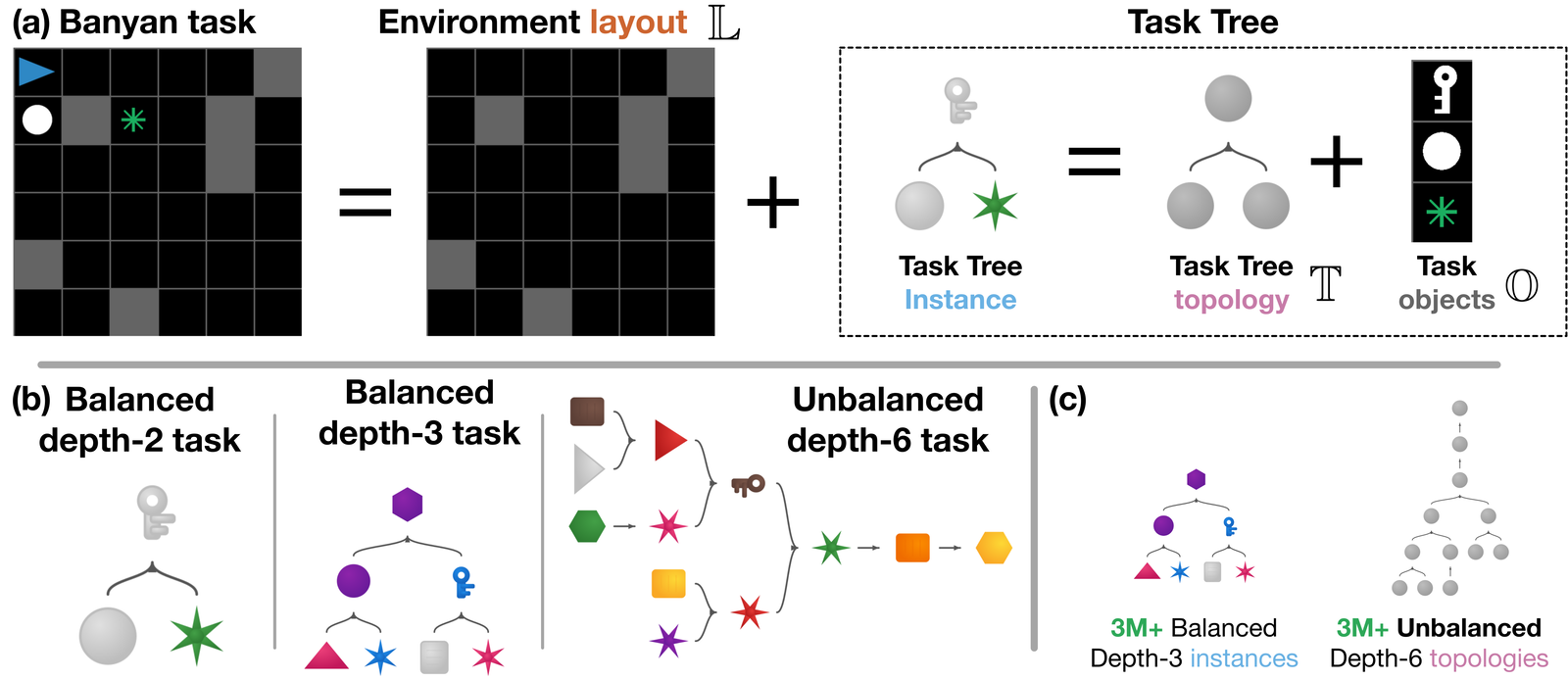
Across a single distribution shift, diversity produces systematic transfer
Start by changing the agent's tasks just once, from a first set to a second. The moment the tasks change, performance usually drops and the agent has to relearn. We call the size of that drop the transfer gap. Increasing the variety along any one of the three ingredients shrinks this gap toward zero. The agent begins the second set near the performance it reached on the first, even when the best strategy for the two sets is different. This holds for both PPO and PQN.
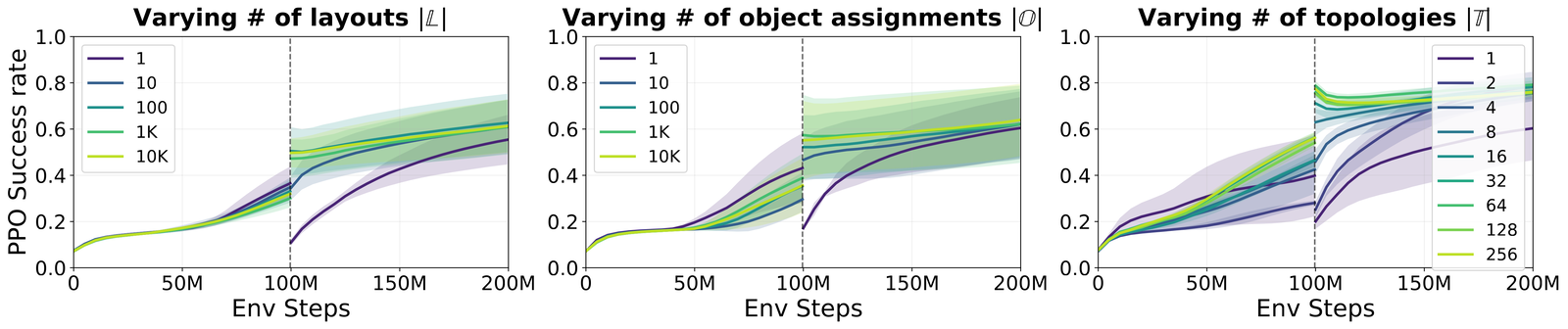
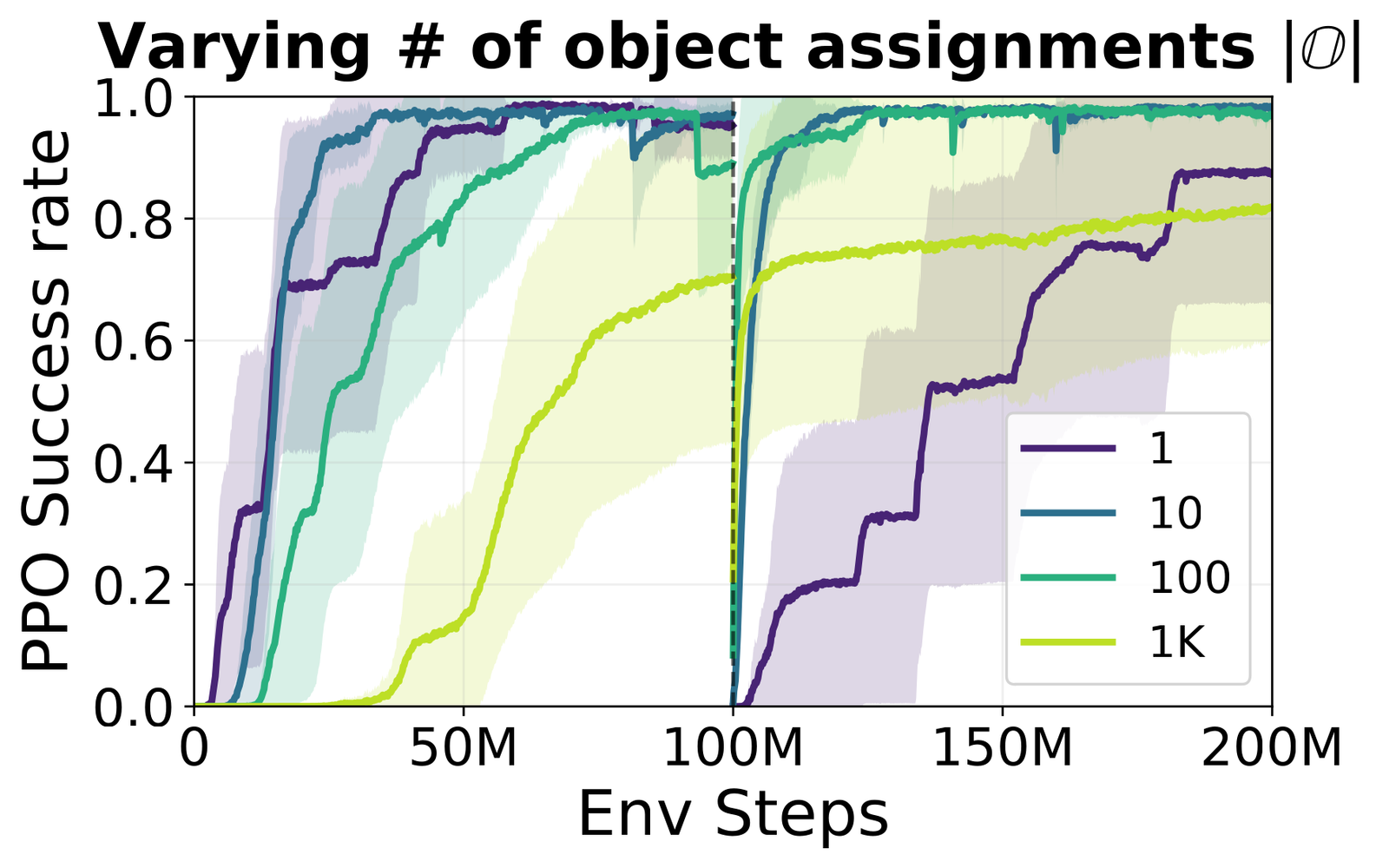
Only varying the number of tree shapes improves backward transfer
Backward transfer reveals a sharper asymmetry. Expanding the number of layouts or object assignments leaves performance on earlier tasks unchanged. Changing topology diversity is the exception: adding more topologies produces a large gain. This pattern holds for both PPO and PQN. What the agent carries forward is compositional structure, not surface detail.

The effect is not an artifact of grid-worlds
We built a continuous-control version of Banyan where the agent drives a point mass to push objects around. The effect persists: more variety still improves both initial performance on new tasks and retention of old ones.
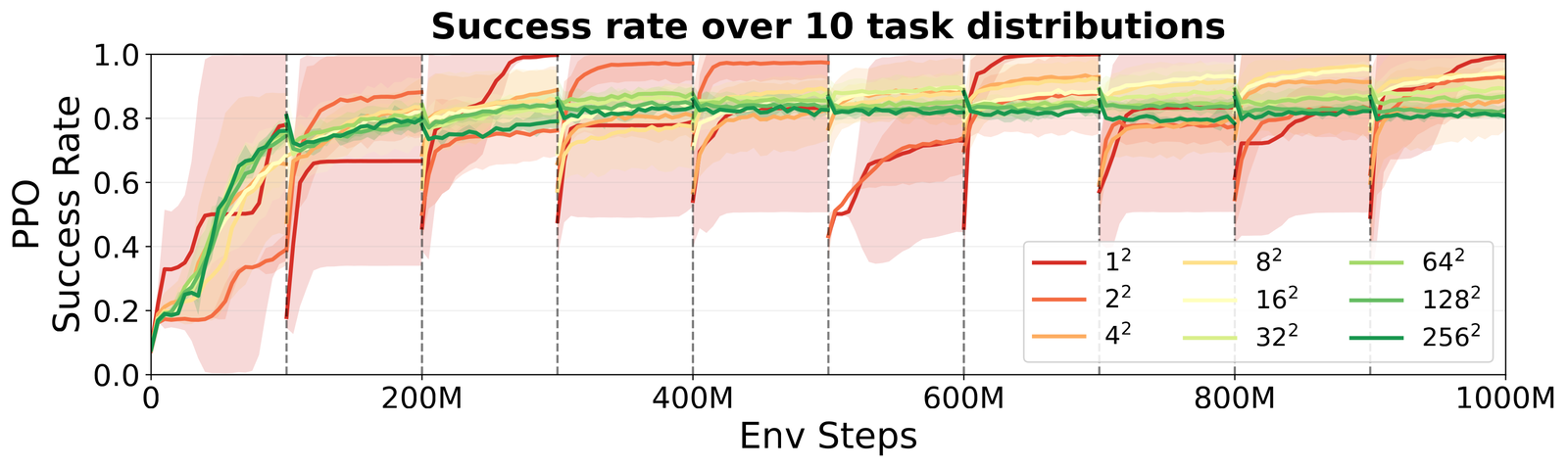
Across ten sets of tasks, variety holds the agent back
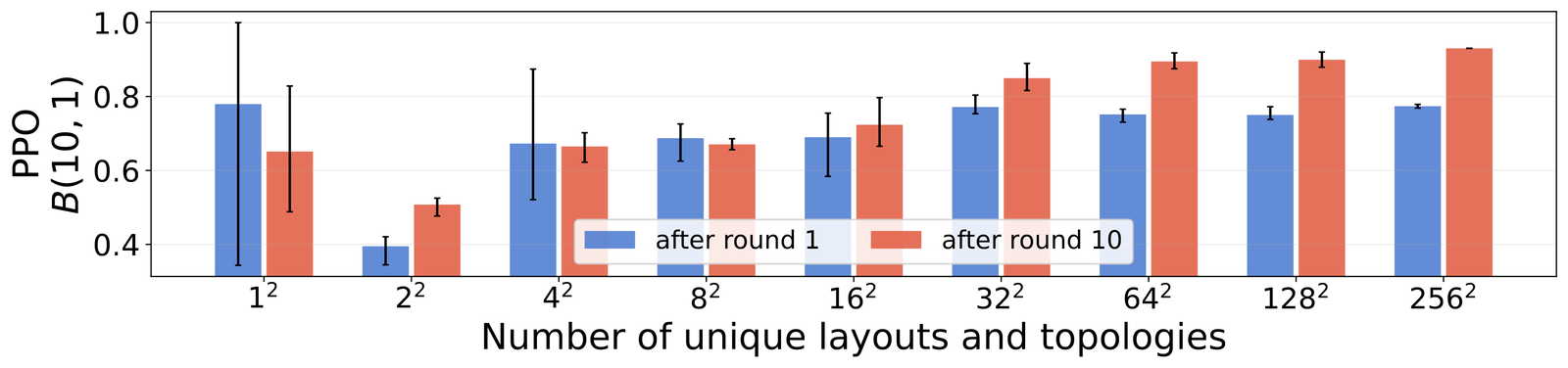
We jointly vary the number of layouts and the number of topologies across ten successive task sets, training a single agent through all ten in turn. We track the success rate the agent achieves by the end of its tenth set. Plotting that success rate against task diversity reveals an inversion: performance climbs to a peak at a moderate level of diversity, then falls as diversity increases further.
At that middle amount of variety (16 layouts by 16 topologies) the final success climbs with each new set of tasks added to training. Past that point, more task diversity steadily lowers it. As variety grows from 16 toward 256 layouts-by-topologies, final success falls across the full range from roughly 0.95 to 0.80. The diversity that helps within any single curriculum ultimately limits what the curriculum can build.
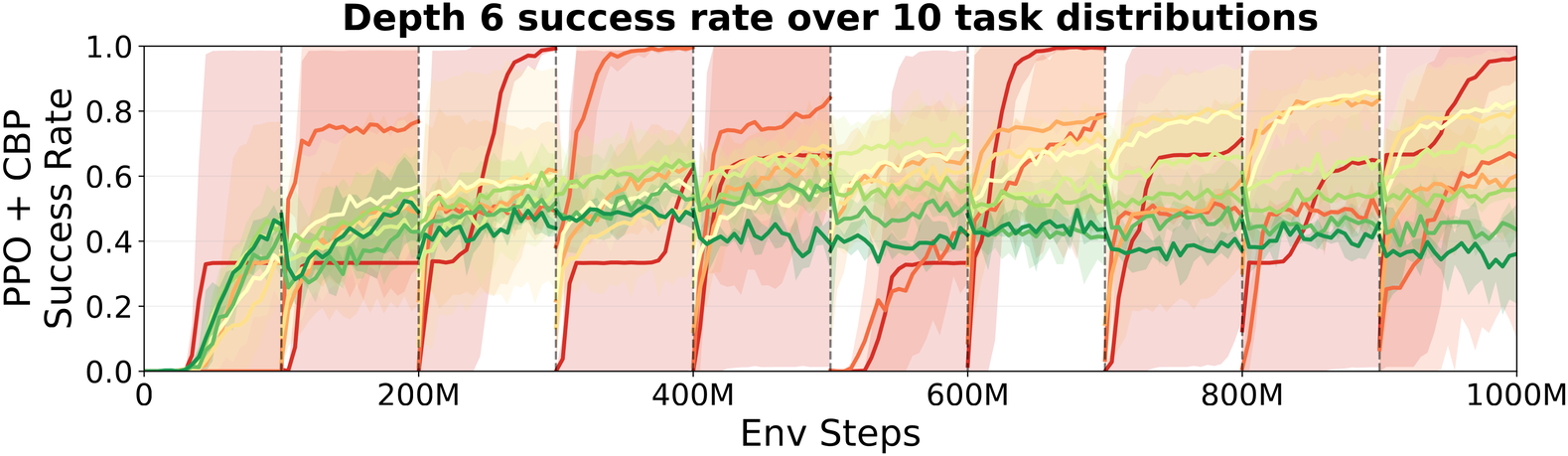
What stalls is not learning, but specialization.
The more task variety an agent has seen, the better it keeps improving on its first set of tasks, even as gains on new ones level off. At the highest variety, the agent is still advancing on old tasks while its progress on new ones plateaus.
The two halves fit together once you see what the agent is learning. The agent picks up the structure shared across tasks, and that shared structure is exactly what lifts the old sets. It loses the ability to specialize to whatever is new in the set in front of it. Varied early sets interfere with later ones. Variety buys a general solution at the cost of a sharp one.
Interested in learning more?
📄 Read the paperBibTeX
@misc{seth2026banyan,
title = {Task diversity produces systematic transfer but
inhibits continual reinforcement learning},
author = {Seth, Purab and Shah, Neil and Jha, Kunal and
Gershman, Samuel J. and Kleiman-Weiner, Max and
Carvalho, Wilka},
year = {2026},
eprint = {2606.00880},
archivePrefix = {arXiv},
url = {https://arxiv.org/abs/2606.00880}
}