
Building Machines that Learn and Think Like People (pt 4. Learning as Rapid Model-Building)
06 Jan 2018 | reviewtags: cognitive-science, machine-learning, brain, deep-learning Note: Ideas and opinions that are my own and not of the article will be in an italicized grey.
Series Table of Contents
Part 1: Introduction and HistoryPart 2: Challenges for Building Human-Like Machines
Part 3: Developmental Software
Part 4: Learning as Rapid Model-Building
Part 5: Thinking Fast
Resources
Glossary
| Article Table of Contents |
|---|
| Compositionality |
| Causality |
| Learning-to-learn |
| References |
Previously, we discussed some skills manifest early in childhood that might play a key role in human-level learning & thinking. Whereas there, the focus was on what type of information the brain may use to bootstrap learning, here we focus on how the brain learns so efficiently. We will try to discuss methods of learning that are potentially useful for the brain, with a particular focus on endowing neural networks with the ability to “rapidly build models”. By this, we mean the ability to quickly learn and construct models for things in the world.
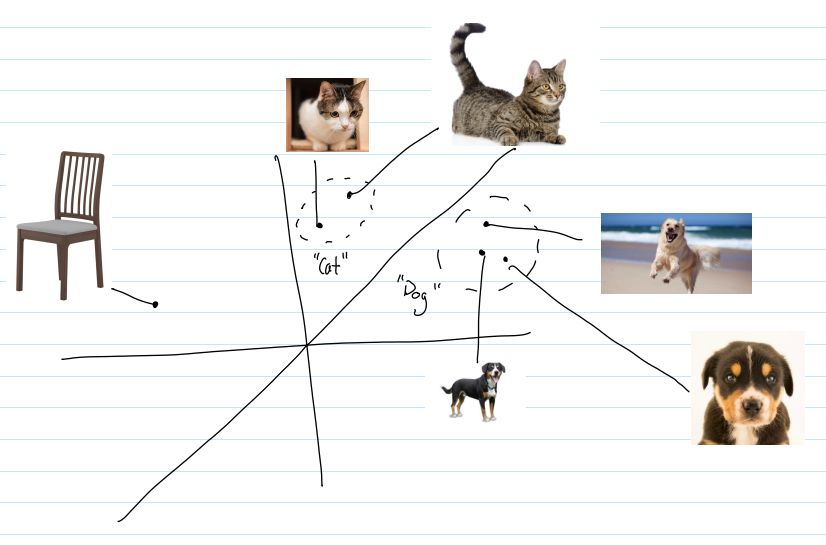
Throughout the history of neural networks, learning has traditionally been characterized by gradual adjustment of network weights (abstractions for their synapses) (Hinton, 2002; Rumelhart et al., 1986). Through gradual weight changing, neural networks have learned to gradually (read slowly) match the statistics of a dataset they’re trained on. However, we know from studies with children that humans have the ability to learn and generalize rapidly from small amounts of data (Carey & Bartlett, 1978). If you imagine that there is some abstract, infinite space which contains representations of all possible objects, humans seem to be able to demarcate the subset of that space which corresponds to a particular category after only a few examples. For example, in the image below, from just seeing a few examples of “dogs”, humans learn that “dogs” belong to a particular region in that space. This reminds me of the stratification found between concept representations with word embeddings. This makes me wonder if humans are learning the demarcation in a naturally occuring space that they'e learning or in a space they fabricate and populate as they learn. Put differently, it makes me wonder if the space below is real and learned by humans or created by humans as they learn to represent and differentiate objects.
{kind=link}
It is clear that neural networks don’t use data as efficiently as humans do. The authors argue that what differentiates humans from neural networks, currently, is that neural networks simply learn to recognize patterns whereas humans learn structured representations or “concepts”. For example, in the diagram below, a character can be represented as a structured combination of strokes. Learning concepts is more flexible because you can, for example, parse a concept into important components or create more sophisticated meta-concepts. To learn concepts, the authors suggest we work to endow neural networks with compositionality, causality, and learning-to-learn.
To showcase the utility of these components, the authors compare learning with a neural network to learning with a probabilistic programming framework they developed known as “Bayesian Program Learning” (BPL) (Lake et al., 2015). Here, concepts are learned as simple, learnable, stochastic programs which are controlled by a meta-program. I will describe the framework in the context of representing the characters in the omniglot dataset as concepts:
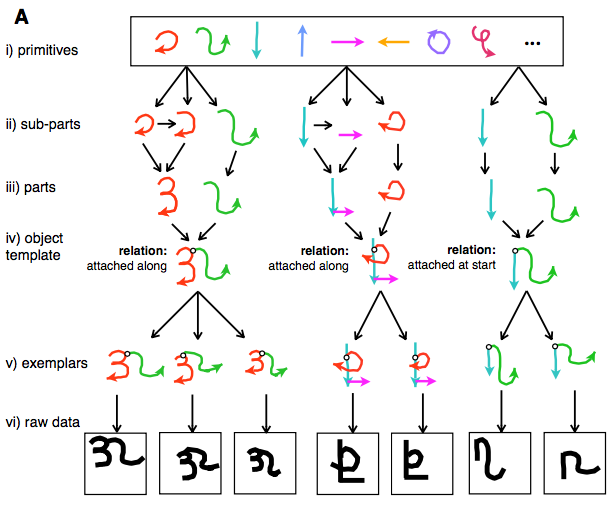
- One program is responsible for representing concepts/object templates.
- There are primitives, which for omniglot represent “fundamental” strokes that can be made for characters.
- Primitives are related and combined to create parts. Parts are then re-related and combined to create templates for a “concept”.
- A meta-program is then responsible for generating a “concept” using the template. This whole process is stochastic because how each component of a concept manifests (or is drawn) is stochastic. For example, in the figure above, you can see possible variations the program might generate for each object template. Clearly there is variation in the angles, lengths, etc. of the strokes for concepts but the general structure is maintained.
Concept learning is then learning these stochastic programs for generating object templates. A key facet of concepts is that their “components” are represented hierarchically. For example, primitives are combined into sub-parts which are combined and related into parts in a hierarchical process. By representing concept learning in this form, BPL is able to re-use prior knowledge (e.g. learned primitives) and learn character concepts using only a few examples similarly to humans.
Compositionality
Compositionality is the classic idea that new representations can be constructed through combinations of primitive elements. Real world examples include sentences which are combinations of words, the “primitives” of language (Fodor, 1975), or programs which are compositions of functions, which are themselves compositions of more primitive data types.
Compositionality has been influential in both artificial intelligence and cognitive science. This paper focuses on it in the context of object representation. Here, “structural description models” have historically assumed that visual concepts could be represented as compositions of parts and relations (Biederman, 1987). For example, a segway can be composed of wheels, connected to a stand and handle.
As a reminder, learning-to-learn is the idea of using learned concepts as “primitives” for other concepts when learning. In the diagram above, once one learns the “primitives”, using them to learn new concepts is “learning-to-learn”. ("Learning-to-learn" actually sounds like a misnomer in this context. You're not learning to learn. You're bootstrapping knowledge. But I digress.) Compositionality and learning-to-learn, as seen by the example above, can naturally go together for learning concepts, especially with a hierarchical structure. This in turn can facilitate generalization to new tasks as previous knowledge is easily built upon and reused.
Neural networks have been shown to have compositionality like functionality as progressively deep layers represent objects as compositions of more primitive features at lower layers. However, neural networks seem to lack the “relation” feature, disallowing them from utilizing compositionality for complex tasks. This seems to no longer be true as capsule networks seem to be able to capture relations between objects. Previously, neural networks would recognize the object in the image below as a face because they learned that faces were compositions of more primitive parts (nose, eyes, lips, etc.). However, capsule networks also learn relations between parts, requiring the components of a face to have roughly correct spatial relations in order for the composition to be classified as a face.

Compositionality in neural networks has a number of utilities. Besides allowing for more sophisticated object recognition, non-visual objects can also be seen from a compositional perspective. For example, completing the level of a video game can be thought of (and possibly learned) as completing a composition of sub-goals (e.g. get to ledge, jump down, jump over enemy, etc.).
Causality
Causal models attempt to abstractly describe the real world process that produces an observation. They are a sub-class of generative models that attempt to describe a process for generating data. They differ in that the process for generating data described by a generative model does not need to resemble the real-world process that generated the data, whereas in causal models, the generative process does need to resemble the real-world process. For example, a model that learns to predict the pixels associated with different character concepts is simply a generative model (e.g. (Kingma, Diederik P & Welling, Max, 2013)); whereas a model that attempts to generate hand-written characters by imitating strokes is a causal model (e.g. (Lake et al., 2015)).
Causal models have been influential in research on perception, particularly in the idea of “analysis by synthesis” (Bever & Poeppel, 2010). It states that sensory data can be more richly represented by modeling the process that generated it. Studies in cognitive science have shown that causal models are important and likely modeled by humans. For example, experiments have shown that changing the causal process for how data is generated can change how humans both learn and generalize what they learn (Rehder, 2003).
Much research indicates that we model the causal process that generated the data we see. For example, when we see images, we often interpret or caption them in the form of an answer to “why is this happening?” (Rehder, 2003). This is something that neural networks currently lack, as evident by the examples of captions generated by neural networks below. While the components in the images are present, their causal relation is missing and leads to wildly inaccurate captions.

While neural networks have had difficulty learning the causal structure in images, one has done a good job with learning causal models for hand-written characters: the DRAW architecture (Rezende et al., 2016). This model was able to learn a causal model for characters and learned to draw characters from only a few examples similarly to the BPL. However, the authors claim that DRAW doesn’t generalize similarly to humans. This is, however, a point of contention (Botvinick et al., 2017), as prominent cognitive scientists and neuroscientists have argued otherwise.
Regardless, neural networks can likely benefit from causality and compositionality. They may facilitate learning-to-learn as it may allow for more primitive concepts to effectively be utilized for explaining new data. They may also facilitate neural networks learning realistic models for how data is produced, and more strongly, they may facilitate learning models for the world and how it changes.
Learning-to-learn
As mentioned before, learning-to-learn is the utilization of prior knowledge in learning a new task. In BPL, this was reusing primitives and learned parts when learning new concepts. In machine learning, this is closely related to “transfer learning”, where you apply knowledge learned from one task to another, “multi-task learning”, where you learn multiple tasks concurrently with the hope that task-constituents are shared and help each other, and “representation learning”, where you seek to learn generalizable representations of data.
In learning-to-learn, hierarchical structure seems to be particularly useful. For example, with BPL, once the parts were learned, hierarchical structure facilitated their reuse for learning new concepts. Further, hierarchical structure allowed for compositionality, causality, and learning-to-learn to naturally work together, acting somewhat like a catalyst for producing a model that could quickly learn new concepts.
While there is much research being done on learning-to-learn, the authors believe this could particularly benefit from compositional, hierarchical, and causal representations. I actually think neural networks already have compositional and hierarchical representations. However, they're missing causality, which I do believe will play a key role. I think this is evident by the captions generated above. Learning-to-learn is particularly important for efficient learning because it allows for the re-use of learned representations for new tasks. The interaction between representations and previous experience may be the key to building machines that learn as fast as people do.
References
- Lake, B. M., Ullman, T. D., Tenenbaum, J. B., & Gershman, S. J. (2016). Building Machines That Learn and Think Like People. The Behavioral and Brain Sciences, 40, 1–101.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6), 533–536.
- Hinton, G. E. (2002). Training Products of Experts by Minimizing Contrastive Divergence. Neural Computation, 14(8), 1771–1800.
- Carey, S., & Bartlett, E. (1978). Acquiring a single new word.
- Lake, B. M., Salakhutdinov, R., & Tenenbaum, J. B. (2015). Human-level concept learning through probabilistic program induction. Science, 350(6266), 1332–1338.
- Fodor, J. A. (1975). The Language of Thought. Harvard University Press.
- Biederman, I. (1987). Recognition-by-components: a theory of human image understanding. Psychological Review, 94(2), 115–147.
- Kingma, Diederik P, & Welling, Max. (2013). Auto-Encoding Variational Bayes. ArXiv.org.
- Bever, T. G., & Poeppel, D. (2010). Analysis by synthesis: a (re-) emerging program of research for language and vision. Biolinguistics, 4(2-3), 174–200.
- Rehder, B. (2003). A causal-model theory of conceptual representation and categorization. Journal of Experimental Psychology. Learning, Memory, and Cognition, 29(6), 1141–1159.
- Rezende, D. J., Mohamed, S., Danihelka, I., Gregor, K., & Wierstra, D. (2016). One-Shot Generalization in Deep Generative Models. ArXiv.org, arXiv:1603.05106.
- Botvinick, M., Barrett, D. G. T., Battaglia, P., de Freitas, N., Kumaran, D., Leibo, J. Z., Lillicrap, T., Modayil, J., Mohamed, S., Rabinowitz, N. C., & others. (2017). Building machines that learn and think for themselves. Behavioral and Brain Sciences, 40.