
Overview of FARM. (a) FARM learns an agent state representation that is distributed across n recurrent mod- ules. (b) By distributing agent state across multiple modules, FARM is able to represent different object-centric task reg- ularities, such as navigating around obstacles or picking up goal keys, across subsets of modules. We hypothesize that this enables a deep RL agent to flexibly recombine its experience for generalization.
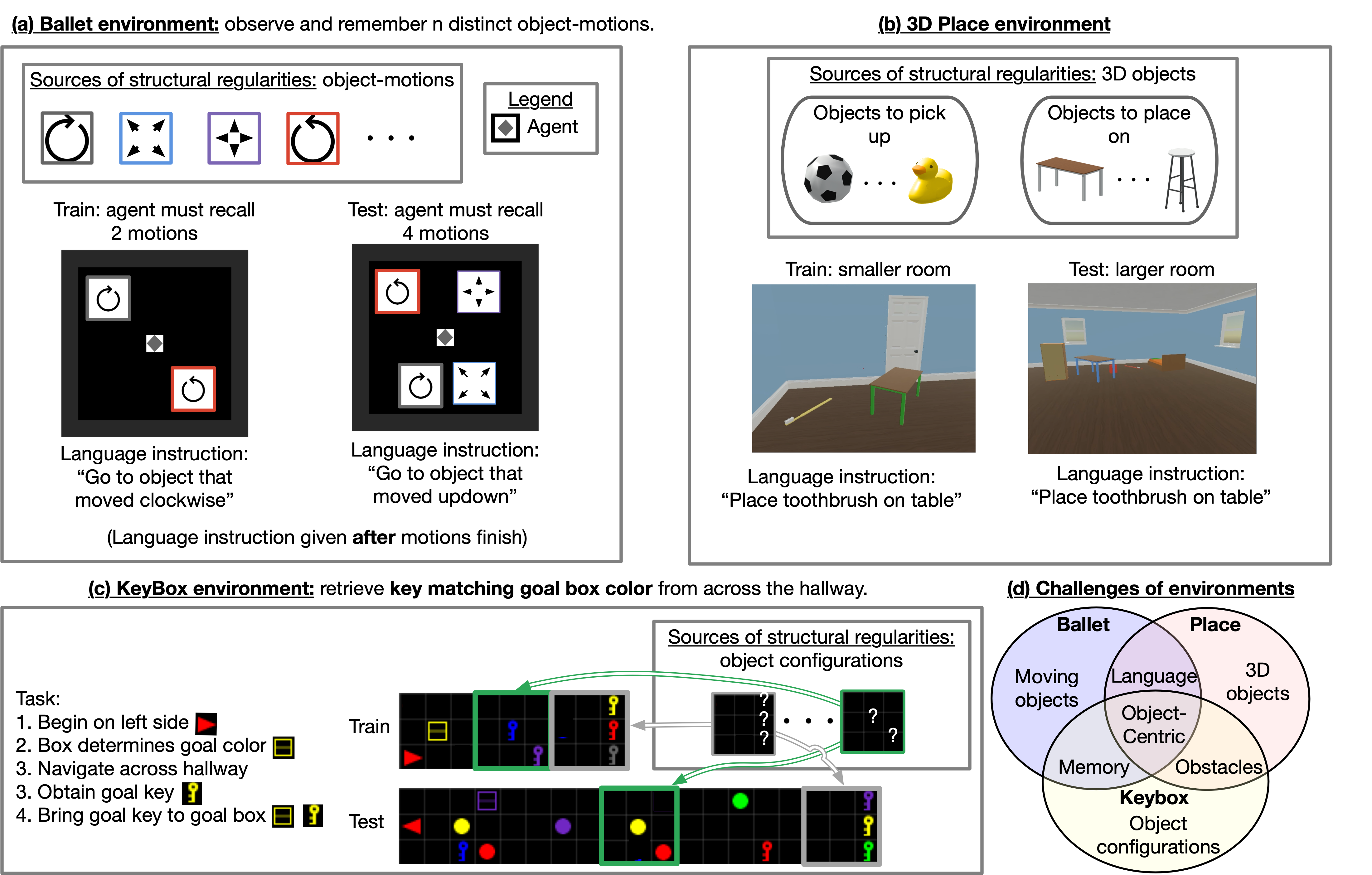
We study three environments with different structural regularities induced by objects. In the Ballet environment, tasks share regularities induced by object motions; in the KeyBox environment, they share regularities induces by object configurations; and in the Place environment, tasks share regularities induces by 3D objects. The Ballet and KeyBox environments pose learning challenges for long-horizon memory and require generalizing to more objects. The KeyBox and Place environments pose learning challenges in obstacle navigation and requires generalizing to a larger map. We provide videos of our agent performing these tasks in the supplementary material.